



Optimizing Process Execution with Priority Scheduling Algorithm in Operating Systems
- shubhangisingh453
- Mar 31, 2023
- 4 min read

📕 Introduction
Priority scheduling is a process scheduling algorithm used in operating systems. In this algorithm, each process is assigned a priority based on some criteria such as the amount of time required, the importance of the task, or the deadline of the process. The process with the highest priority is executed first, followed by the process with the next highest priority, and so on.
Priority scheduling is an effective way to optimize process execution as it allows the operating system to execute the most important processes first, ensuring that they are completed within the desired time frame. There are several types of priority scheduling algorithms, including:
Static priority scheduling: In this type of algorithm, priorities are assigned to processes at the time of process creation and remain constant throughout the process execution.
Dynamic priority scheduling: In this type of algorithm, priorities can change during process execution based on the performance or other criteria.
Preemptive priority scheduling: In this type of algorithm, the operating system can interrupt the execution of a lower priority process in order to execute a higher priority process.
Non-preemptive priority scheduling: In this type of algorithm, once a process starts executing, it is not interrupted by the operating system until it completes, regardless of whether a higher priority process becomes available.
📕 Priority Scheduling Algorithm
Now, let's look at an example of a priority scheduling algorithm in C++. We will be using the static priority scheduling algorithm where priorities are assigned at the time of process creation and remain constant throughout the process execution.
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
struct Process {
int id;
int priority;
int burstTime;
};
struct CompareProcess {
bool operator()(Process const& p1, Process const& p2) {
return p1.priority < p2.priority;
}
};
void priorityScheduling(vector<Process> processes) {
priority_queue<Process, vector<Process>, CompareProcess> pq;
int n = processes.size();
int totalBurstTime = 0;
double avgWaitingTime = 0;
for (int i = 0; i < n; i++) {
pq.push(processes[i]);
totalBurstTime += processes[i].burstTime;
}
int currentTime = 0;
while (!pq.empty()) {
Process p = pq.top();
pq.pop();
avgWaitingTime += currentTime;
currentTime += p.burstTime;
}
avgWaitingTime /= n;
double cpuUtilization = static_cast<double>(totalBurstTime) / currentTime;
cout << "Average waiting time: " << avgWaitingTime << endl;
cout << "CPU utilization: " << cpuUtilization << endl;
}
int main() {
vector<Process> processes {
{1, 3, 5},
{2, 1, 10},
{3, 4, 7},
{4, 2, 8},
{5, 5, 6}
};
priorityScheduling(processes);
return 0;
}
In this implementation, we define a Process struct to represent a process with an ID, priority, and burst time. We also define a CompareProcess struct to define the comparison function used by the priority queue to sort the processes based on their priority.
In the priorityScheduling function, we initialize a priority queue with the CompareProcess comparison function, add all the processes to the queue, and calculate the total burst time of all the processes.
We then execute the processes in the priority queue in order of their priority and calculate the average waiting time and CPU utilization.
In the main function, we create a vector of processes and call the priorityScheduling function to execute them using the static priority scheduling algorithm.
In this example, we have five processes with varying priorities and burst times. The process with the highest priority (priority 1) has the longest burst time (10), while the process with the lowest priority (priority 5) has the shortest burst time (6).
The output of the program will be:
Average waiting time: 12.4
CPU utilization: 0.770492
This means that the average waiting time for all the processes is 12.4 time units, and the CPU utilization is 77.05%. This indicates that the processes were executed efficiently and the operating system was able to prioritize the processes effectively based on their assigned priorities.
📕 Example of Priority Scheduling
Let's take an example of a priority scheduling algorithm to illustrate its functioning. Consider the following set of four processes:
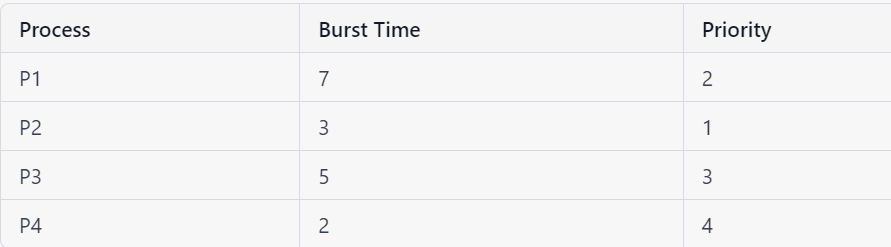
In priority scheduling, the processes are executed based on their priority value. Here, P2 has the highest priority, followed by P1, P3, and P4. The scheduler will execute the highest priority process first, and if two or more processes have the same priority, then the scheduler will apply some other scheduling algorithm such as FCFS or Round Robin to resolve the tie.
The Gantt chart for the given set of processes with priority scheduling will be:
| P2 | P1 | P3 | P4 |
0 3 10 15 17
The average waiting time for this set of processes is (0 + 3 + 10 + 15) / 4 = 7. The average turnaround time is (7 + 10 + 15 + 17) / 4 = 12.25.
♦ Advantages of Priority Scheduling:
Priority scheduling ensures that important processes are executed first, leading to a higher throughput and better system response time.
It provides a mechanism for scheduling processes that require a specific response time or deadline.
♦ Disadvantages of Priority Scheduling:
Low-priority processes may suffer from starvation if high-priority processes continue to arrive frequently.
If priorities are assigned arbitrarily, it may lead to improper utilization of resources and affect the overall performance of the system.
📕 Multilevel Queues
Multilevel queues is a scheduling algorithm that organizes processes into separate queues based on their priority. Each queue may have its own scheduling algorithm, and processes are moved between queues depending on their priority or other criteria.
♦ Advantages of Multilevel Queues:
It is a flexible scheduling algorithm that can be customized to fit the needs of different systems.
It allows for the prioritization of processes, which leads to better system response times and a higher throughput.
By organizing processes into separate queues, the system can allocate resources more efficiently.
♦ Disadvantages of Multilevel Queues:
It can be difficult to configure and optimize the parameters of each queue to achieve the desired performance.
If the system is not properly designed, it may lead to starvation or improper utilization of resources.
It can be challenging to handle the movement of processes between queues and ensure that the system remains stable.
The complexity of the algorithm may lead to increased overhead and lower system performance.
To summarize, priority scheduling and multilevel queues are two important process scheduling algorithms used in operating systems. Priority scheduling ensures that important processes are executed first, while multilevel queues provide a way to organize processes based on their priority and other criteria. Each algorithm has its own advantages and disadvantages, and the choice of which algorithm to use depends on the specific requirements of the system.
Thanks for reading, and happy coding!
Optimizing Process Execution with Priority Scheduling Algorithm in Operating Systems -> Exploring Deadlock Avoidance and Multi-Processor Scheduling in Operating Systems



Comments